1 数据库概论
本文最后更新于:2025年11月25日 下午
一、数据库基本概念
(一)核心定义
- 数据(Data):事物的符号表示,涵盖数字、文字、图像、声音等,可经数字化以二进制形式存入计算机处理。
- 数据库(DB):长期存于计算机内、有组织且可共享的数据集合,按特定数据模型组织、描述和储存,具有低冗余度、高数据独立性与易扩张性。
- 数据库管理系统(DBMS):数据库系统的核心系统软件,需操作系统支持,实现用户对数据库的操作,核心功能如下:
- 数据定义:提供数据定义语言,定义数据库及数据库对象。
- 数据操纵:提供数据操纵语言,实现数据的查询、插入、修改、删除。
- 数据控制:提供数据控制语言,保障数据安全、完整性及并发控制。
- 数据库建立维护:含初始数据装入、转储、恢复及系统性能监视分析。
- 数据库系统(DBS):引入数据库后的计算机系统,由数据库、操作系统、DBMS、应用程序、用户、数据库管理员(DBA)组成。
(二)数据库应用系统架构
| 架构类型 | 核心逻辑 | 特点 |
|---|---|---|
| 客户/服务器(C/S)架构 | 应用程序发送数据请求→DBMS分析执行→返回处理结果 | 直接交互,适用于对响应速度要求较高的场景 |
| 浏览器/服务器(B/S)架构 | 基于Web的三层架构(浏览器→Web服务器→数据库服务器) | 无需安装客户端,通过浏览器即可访问,维护成本低 |

图1:浏览器服务器(BS)架构图
(三)数据管理技术发展阶段
- 人工管理阶段(20世纪50年代中期前):数据面向应用程序,一个数据集仅对应一个程序,数据与程序紧密耦合。
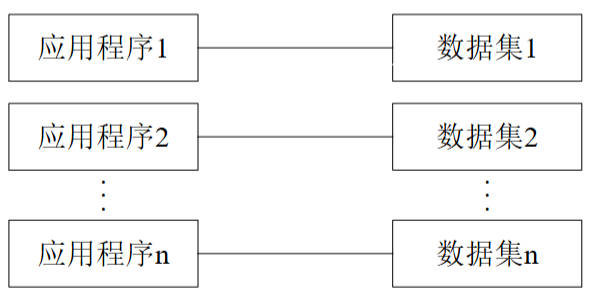
图2:人工管理阶段应用程序与数据应用之间的关系
- 文件系统阶段(20世纪50年代后期-60年代中期):计算机用于数据管理,处理方式含批处理与联机实时处理,通过文件系统管理数据,应用程序与数据仍存在一定依赖。
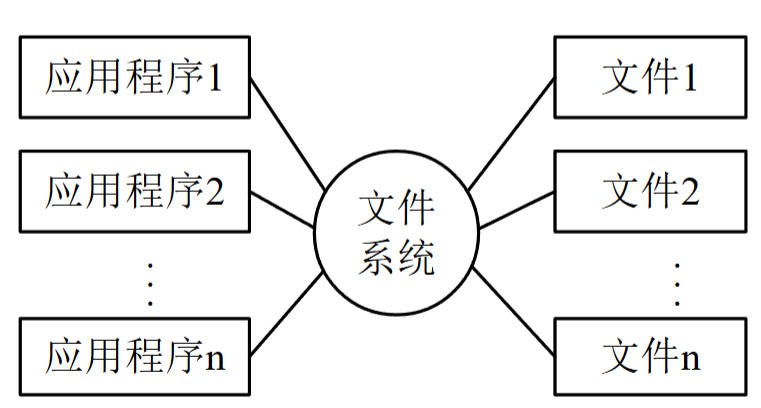
图3:文件系统阶段应用程序与数据之间的关系
- 数据库系统阶段(20世纪60年代后期起):为解决多用户、多应用共享数据需求,DBMS出现,实现数据统一管理,应用程序通过DBMS访问数据库,降低数据与程序耦合度。
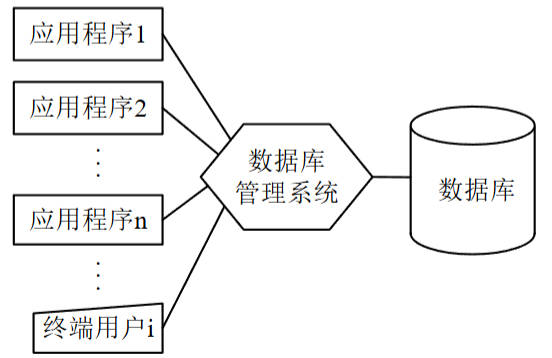
图4:数据库阶段应用程序与数据之间的关系
二、数据模型
(一)概述
- 定义:对现实世界数据特征的抽象,用于描述、组织数据及对数据操作,是数据库系统的核心与基础。现实世界数据需经“现实世界→信息世界(概念模型)→计算机世界(逻辑模型)”三阶段转换。
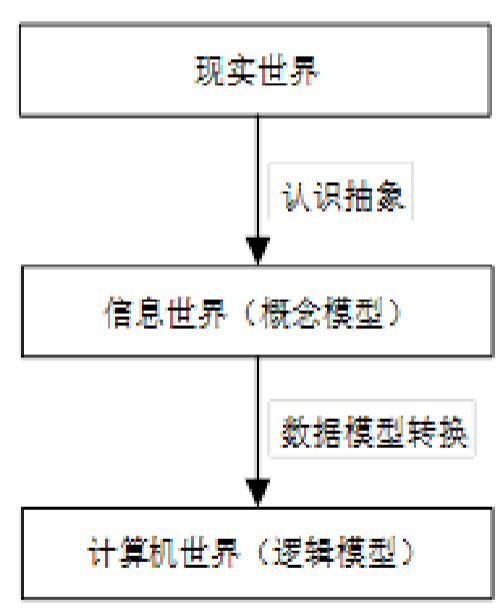
图5:数据模型
- 分类:按应用层次分概念模型、逻辑模型、物理模型。
- 组成要素:含数据结构、数据操作、数据完整性约束三部分。
(二)概念模型
- 核心概念:对现实世界的第一层抽象(又称信息模型),用于数据库设计人员与用户交流,核心概念包括实体、属性、实体型、实体集、联系。
- 实体联系类型
- 一对一(1:1):如一个班仅一个正班长,一个正班长仅属一个班。
- 一对多(1:n):如一个班有多个学生,一个学生仅属一个班。
- 多对多(m:n):如一个学生可选多门课,一门课可被多个学生选。
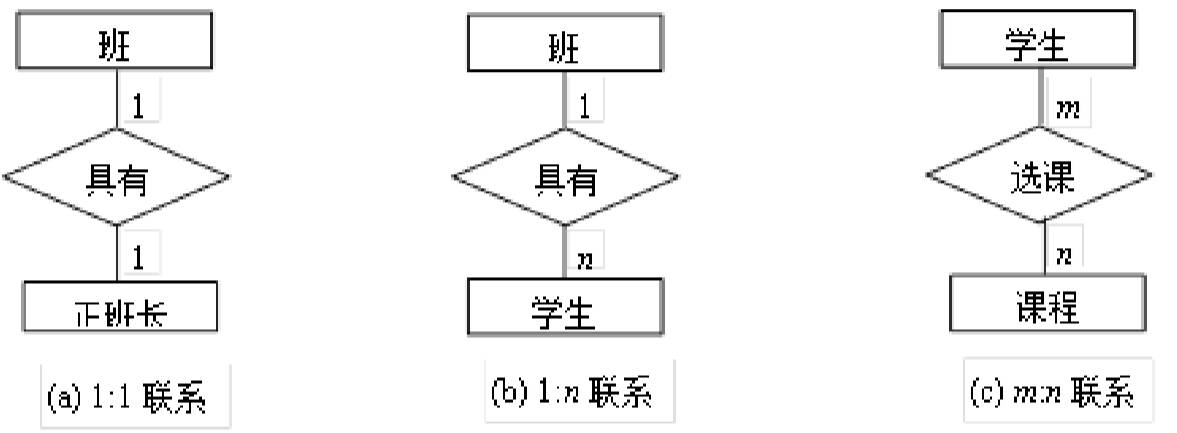
图6:实体之间的三种联系
- 表示方法(E-R图)
- 实体:矩形框,框内标实体名。
- 属性:椭圆框,框内标属性名,用无向边连对应实体。
- 联系:菱形框,框内标联系名,用无向边连参与联系的实体,标注联系类型(1:1、1:n、m:n),联系属性用无向边连菱形框。
(三)逻辑模型
| 模型类型 | 数据组织方式 | 特点 | 示例 |
|---|---|---|---|
| 层次模型 | 树状层次结构,仅一个根节点,其他节点仅一个父节点 | 简单易用,但难表达非层次性联系(如多对多) | 某大学组织结构(大学→学院→专业→学生) |
| 网状模型 | 网状结构,节点可有多条联系 | 能直接描述复杂现实关系,层次模型是其特例,但结构复杂、难掌握 | 教师、课程、学生间的多向关联 |
| 关系模型 | 二维表(关系),表由行和列组成 | 基于严格数学概念,数据结构清晰,易懂易用,应用最广泛 | 学生表(学号、姓名、性别等)、成绩表(学号、课程号、成绩等) |
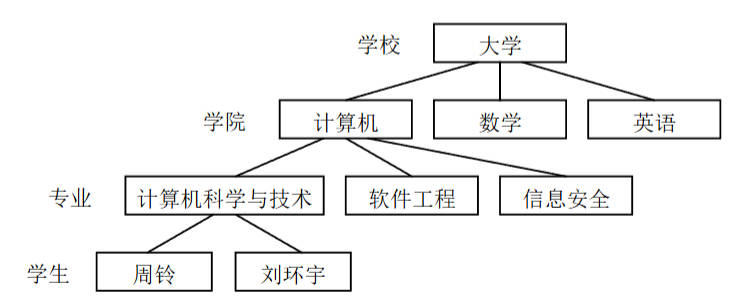
图7:层次模型
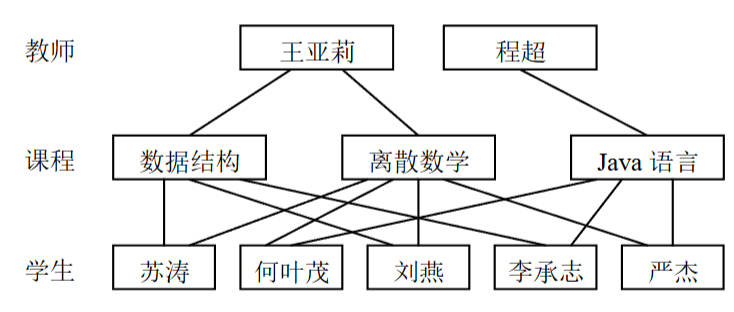
图8:网状模型
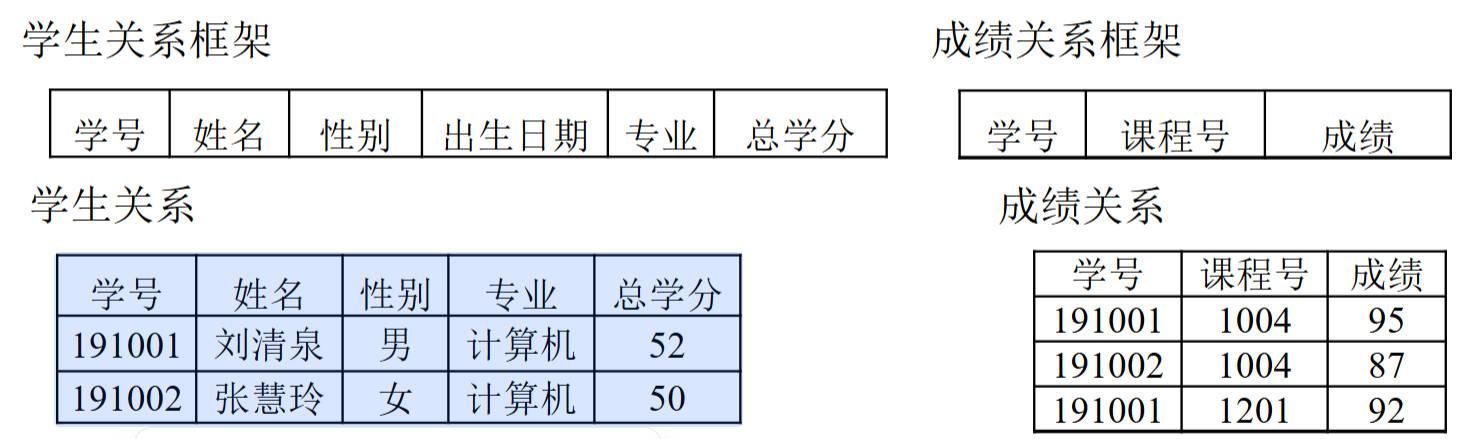
图9:关系模型
三、数据库系统结构
(一)三级模式结构
- 外模式(子模式/用户模式):对应用户级,是用户所见的数据视图,为模式的子集,一个数据库可有多外模式,一个应用程序仅用一个外模式,由外模式DDL描述定义。
- 模式(概念模式/逻辑模式):对应概念级,是数据库设计者构建的全局逻辑结构,为所有用户的公共数据视图,一个数据库仅一个模式,由模式DDL描述定义。
- 内模式(存储模式):对应物理级,描述数据物理结构与存储方式,是数据在数据库内部的表示,一个数据库仅一个内模式,由内模式DDL描述定义。
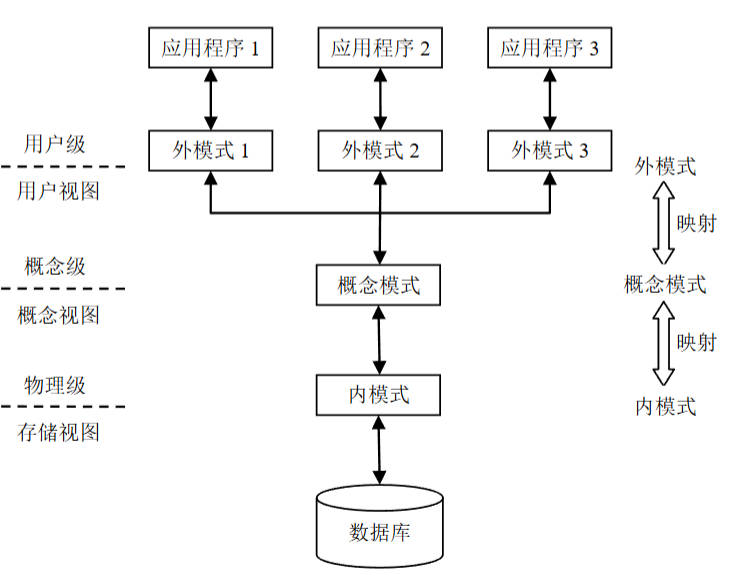
图10:数据库系统的三级模式结构
(二)二级映像与数据独立性
- 外模式/模式映像:定义外模式与模式的对应关系。模式改变时,DBA调整该映像可使外模式不变,保障数据与程序的逻辑独立性(应用程序基于外模式编写,无需修改)。
- 模式/内模式映像:唯一,定义全局逻辑结构与存储结构的对应关系。存储结构改变时,DBA调整该映像可使模式不变,保障数据与程序的物理独立性(应用程序无需修改)。
(三)DBMS工作过程(以读记录为例)
- 应用程序A向DBMS发出从数据库中读用户数据记录的命令;
- DBMS对该命令进行语法检查、语义检查,并调用应用程序A对应的子模式,检查A的存取权限,决定是否执行该命令。如果拒绝执行,则转(10)向用户返回错误信息。
- 在决定执行该命令后,DBMS调用模式,依据子模式/模式映象的定义,确定应读入模式中的哪些记录;
- DBMS调用内模式,依据模式/内模式映象的定义,决定应从哪个文件、用什么存取方式、读入哪个或哪些物理记录;
- DBMS向操作系统发出执行读取所需物理记录的命令。
- 操作系统执行从物理文件中读数据的有关操作;
- 操作系统将数据从数据库的存储区送至系统缓冲区;
- DBMS依据内模式/模式、模式/子模式映象的定义(仅为模式/内模式、子模式/模式映象的反方向,并不是另一种新映象),导出应用程序A所要读取的记录格式;
- DBMS将数据记录从系统缓冲区传送到应用程序A的用户工作区;
- DBMS向应用程序A返回命令执行情况的状态信息。
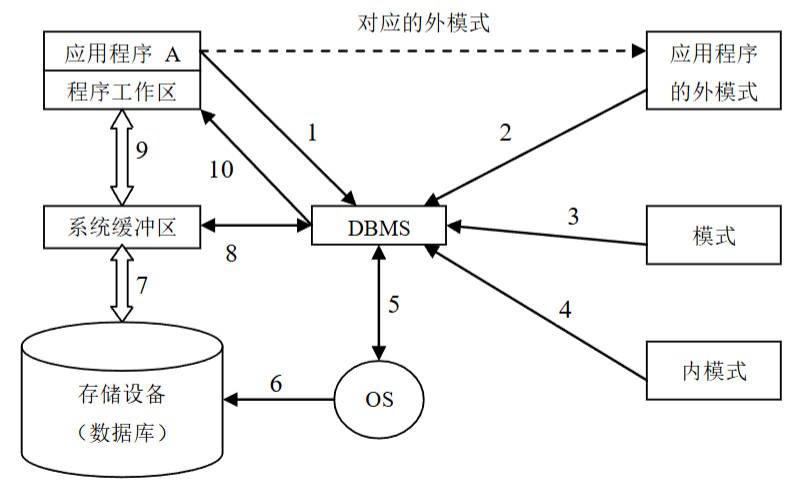
图11:数据库管理系统的工作过程
四、大数据简介
(一)基本概念与特点
- 定义:指海量/巨量数据,需新计算模式进行获取、存储、管理、处理及提炼以辅助决策。维基百科定义为“数据集规模超常用工具在可接受时间内的采集、管理、处理能力”;NIST强调其“巨量(Volume)、多样(Variety)、快速(Velocity)、多变(Variability)”特性。
- 4V+1C特点
- 巨量(Volume):数据量达PB(1PB=1024TB)、EB(1EB=1024PB)级,PB级为常态;
- 多样(Variety):数据来源与格式多样,含结构化、半结构化(如日志)、非结构化数据(如音视频);
- 快速(Velocity):数据增长快,需快速处理以提取价值;
- 价值(Value):需挖掘海量数据的潜在价值;
- 复杂(Complexity):数据处理与分析难度高。
(二)处理过程
- 数据采集与预处理
- 采集:通过多数据库接收智能终端、移动APP、网页端、传感器等数据;
- 预处理:含数据清理(标准化格式、去异常/重复数据、纠错)、数据集成(合并多源数据建数据仓库)、数据变换(平滑、泛化、规范化以适配挖掘)、数据归约(精简数据规模,保留有用特征)。
- 大数据分析
- 统计分析:用分布式数据库/计算集群分析数据,常用R语言(免费开源,用于统计计算与制图);
- 数据挖掘:无预设主题,通过分类(将未知样本映射到已知类别)、聚类(相似数据聚为一类)、关联分析(找数据项间隐藏规则)、预测建模(预测未来结果)等方法找数据模式与趋势。
- 数据可视化:用图形、图像技术直观表达数据,助力发现数据隐含规律。
(三)技术支撑
- 计算速度提升:Hadoop(分布式架构)、Spark(内存集群计算)、HDFS(海量存储)、MapReduce(并行计算)等技术提高计算效率,解决实时分析差、处理效率低等问题。
- 存储成本下降:云计算数据中心降低企业计算与存储成本,如租用硬件无需购服务器及雇人维护,可长期存历史数据。
- 人工智能需求:大数据为AI提供数据基础,如AlphaGo、阿里云小Ai等案例体现AI与大数据的结合。
(四)NoSQL与NewSQL数据库
- 传统关系数据库问题:读写速度慢(数据量大时I/O瓶颈)、支撑容量有限(亿级记录查询效率低)、扩展困难(需停机维护)、管理运营成本高,且复杂SQL查询在大数据场景作用有限。
- NoSQL数据库
- 定义:泛指非关系型数据库(Not Only SQL),常用模型有Cassandra、Hbase、Redis等。
- 特点:读写快、容量大;易扩展(动态增删节点无需停机);遵循BASE原则(基本可用、柔性状态、最终一致);数据模型灵活(无需预定义模式);高可用(多节点备份)。
- 分类:键值(Key-Value)模型(如Redis,查改快)、列存储模型(如Cassandra,适数据仓库)、文档型模型(如MongoDB,存Json/XML文档)、图模型(如Neo4j,直观表达数据联系)。
- NewSQL数据库:结合SQL与NoSQL优势,解决NoSQL通用性差、不支持SQL及ACID特性的问题,代表模型有VoltDB、Spanner。
1 数据库概论
https://hellowydwyd.github.io/2025/10/23/1-数据库概论/